文章来源:
小肖
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至405936398@qq.com举报,一经查实,本站将立刻删除。
_理财保险_转赚网")
提出一个问题,给你两个字符串 s 和 p(p 的长度不超过 s 的长度,且 s 和 p 都不是空的),问 s 中是否包含 p?
例如:
能否写出一个程序高效地解决这个问题。
我们能容易想到这样的方法:
设置两个指针,i 和 j,都初始化为 0,我们对比 s 在 i 位置,p 在 j 位置的字符。如果 s[i] == p[j],那么 i 和 j 都移到下一个位置。否则 j 回退到 0,i 回退到 1,继续上述过程,如果在下一次比较中,还是出现了不匹配的字符,那么 j 回退到 0,i 回退到 2,继续……,周而复始。直到某一次匹配中,如果 j 到达越界位置,那么 s 包含 p,否则 s 不包含 p。代码如下:
public class StrContains { public static boolean contains(String s, String p) { int ls = s.length(), lp = p.length(), i = 0, j = 0; while(i <= ls - lp) { int x = i; j = 0; while(j < lp && s.charAt(x) == p.charAt(j)) { ++x; ++j; } if(j == lp) return true; ++i; } return false; }}这样的查找方法,在遇到 s = “aaaaaaaaaaaaab”,p = “aab” 这样的情况的时候,会使得 p 只有在最后一次匹配的时候,才可以得到匹配。假设 s 的长度是 N,p 的长度是 M,那么显然的最坏情况下时间复杂度就是 O(N∗M)。而 KMP 算法能做到最坏情况下 O(N+M) 的时间复杂度。它是怎么做的呢?我们一起来看看吧。

KMP 算法的计算过程
启发的过程:上面的暴力方法是基于这样的一个尝试的思路,如果 s 中有一个子串和 p 是匹配的,因为任何一个子串都有一个开头位置,那么这个和 p 匹配的子串当然也有一个开头位置,又因为我们不知道哪个开头位置的子串和 p 是匹配的,因此我们尝试所有可能的开头。如果我们尝试完所有的开头位置,都没有发现一个子串可以和 p 匹配,那么 s 中就没有一个子串和匹配,即 s 不包含 p,反之 s 包含 p。那么这个过程它为什么低效呢?我们来看一下 s = “aaaaaaaaab” 和 p = “aaab” 的匹配过程。
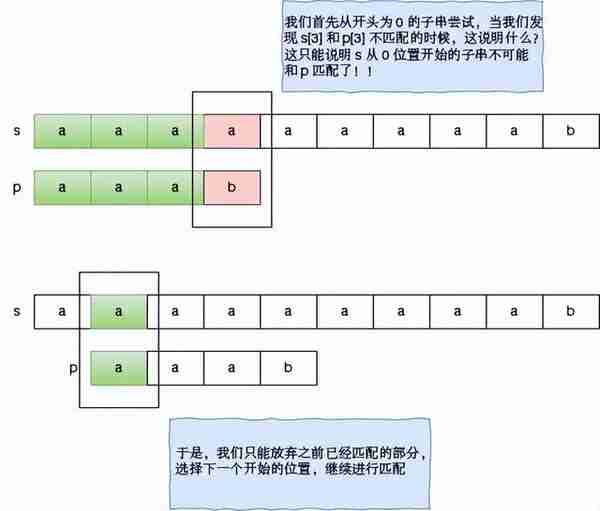
当我们发现某一个开头的尝试已经宣告失败的时候,此时只能选择下一个开头,继续从头开始匹配。那么此时指向 s 的指针会回退,之前已经匹配的部分结果完全抛弃,从新开始,因此这个方法是低效的。
如果某一次尝试失败了,那么之前已经匹配的部分(之前做过的努力)能否给我们提供一些帮助,加速我们的匹配过程,甚至能使得字符串 s 上的指针不回退呢?我们调整的时候,需要遵循什么原则呢?
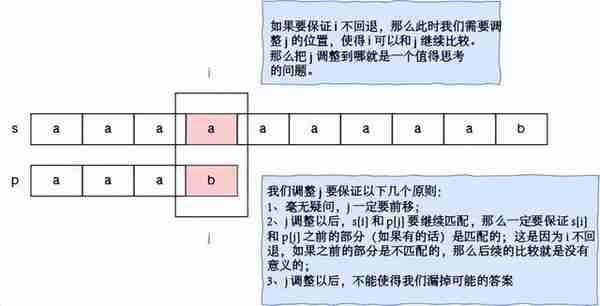
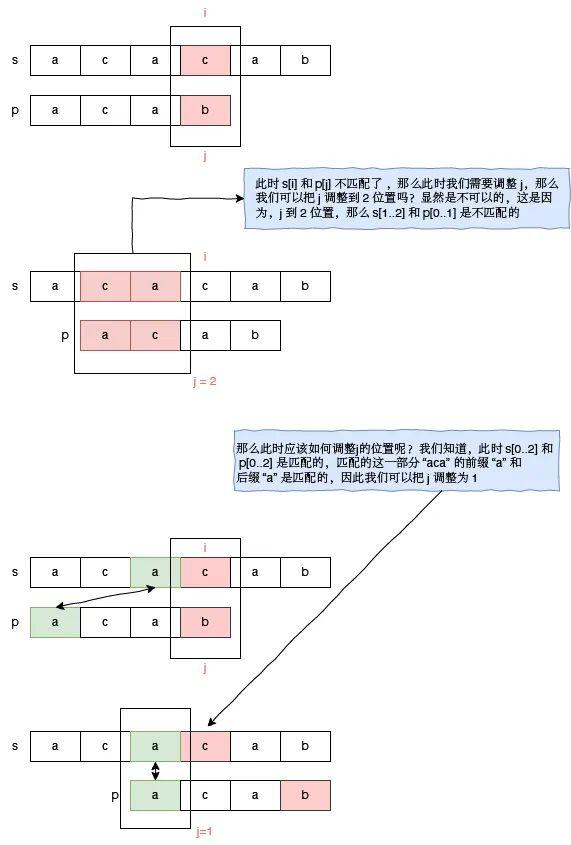
为了便于说明 j 的调整,下面我们举一个明显的例子。请看字符串 s = “acacab”,和字符串 p = “acab” 的匹配过程。
那么如果已经匹配的部分有多个前缀和后缀是匹配的呢?我们怎么选择?请看 s = “aaaab” 和 p = “aaab” 的匹配过程。
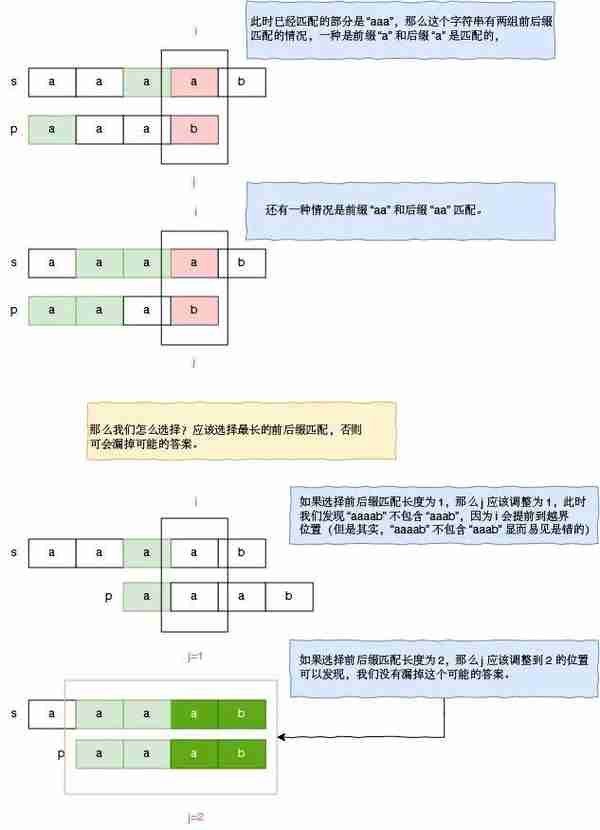
总结一下:此时我们似乎找到了,保证 s 指针不回退的时候,p 的指针的调整方案,即当我们发现某一次匹配失败的时候,我们需要找出前面已经匹配部分的 前后缀最大匹配长度,假设为 next,那么我们只需要把 j 调整为 next,继续进行匹配操作即可。

next 数组
我们在进行真正的匹配之前,我们要先计算好,每一个元素的 next 值(next 值的含义就是当前元素失去匹配的时候,它前面部分字符串的前后缀最大匹配长度,这个前后缀不包含自己),看下面对字符串 “caccacb” 的 next 值的定义过程:
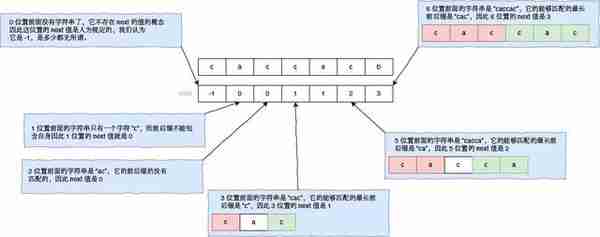
使用 next 数组加速匹配过程
如果我们在匹配之前,得到这么一个关于模式 p 的每一个位置 index 失去匹配后,模式串的匹配指针应该调整为 next[index] 的 next 数组的话,那么我们的匹配过程可以变成这样:
代码
public class StrContainsKmp { public static boolean contains(String s, String p) { int ls = s.length(), lp = p.length(), i = 0, j = 0; int[] next = getNext(p);//获取关于模式串p的next数组 while(i <= ls - lp && j < lp) { if(s.charAt(i) == p.charAt(j)) { ++i; ++j; /* 如果模式串p的第一个字符p[0]和字符串s的当前字符s[i]都不匹配, 那么说明s中从i开始不可能匹配出p来,因此换下一个开头继续尝试 */ }else if(j == 0) ++i; /* 否则j位置不是0,说明它前面有匹配成功的部分, 那么此时j应该调整为next[j]的位置 */ else j = next[j]; } return j == lp; }}next 数组能加速匹配过程,可以从下面两个方面来理解:
在我们匹配失败的时候,它可以利用我们之前已经匹配的部分字符串(以前做过的努力),在保证 i(字符串 s 的匹配指针)不回退的情况下,指导此时指针 j(模式串的匹配指针)应该做怎样的调整。前面的图示已经向大家说明了这一点。
还记得我们的暴力做法吗?它尝试字符串 s 中每一个可能的开头位置(即验证所有的可能性),而 next 数组指导 j 的调整,可以跳过一些根本不可能匹配出来模式串 p 的位置,如下图所示:
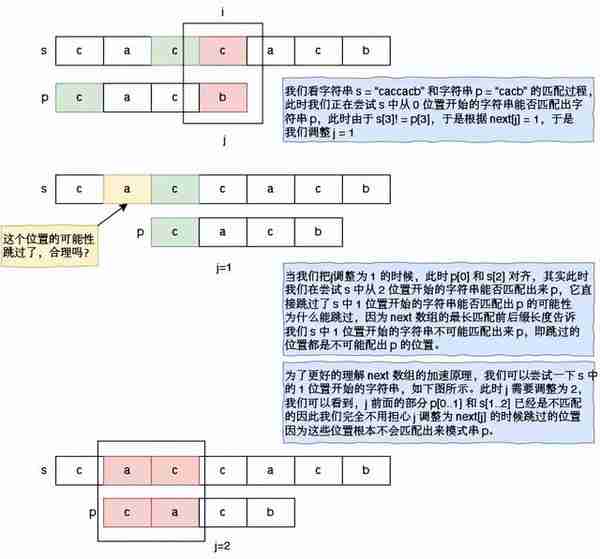
这两种理解是等价的。
next 数组正确性分析
上面我们举了一个例子说明 next 数组能够指导j指针的调整,同时保证 i 指针不回退,并且还能跳过那些不可能的开头位置。那么为什么呢?我们这里给出一般性的说明。如图所示:
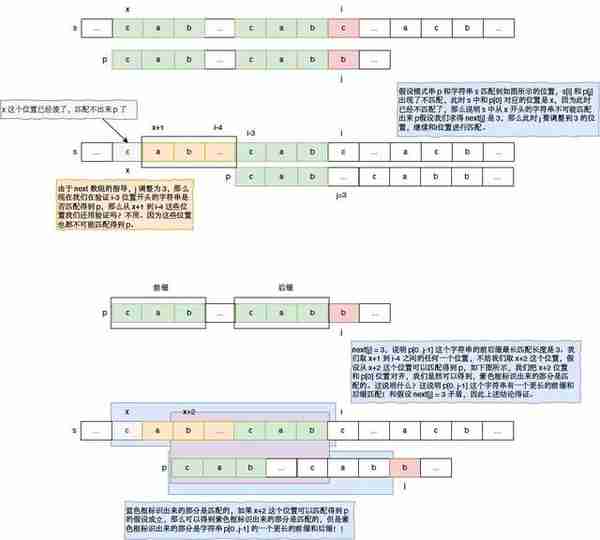
求解 next 数组
既然 next 数组这么好用,我们如何快速得到它呢?


代码和测试程序
public class StrContainsKmp { public static boolean contains(String s, String p) { int ls = s.length(), lp = p.length(), i = 0, j = 0; int[] next = new int[lp]; getNextArray(p, next);//获取关于模式串p的next数组 while(i < ls && j < lp) { if(s.charAt(i) == p.charAt(j)) { ++i; ++j; /* 如果模式串p的第一个字符p[0]和字符串s的当前字符s[i]都不匹配, 那么说明s中从i开始不可能匹配出p来,因此换下一个开头继续尝试 */ }else if(j == 0) ++i; /* 否则j位置不是0,说明它前面有匹配成功的部分, 那么此时j应该调整为next[j]的位置 */ else j = next[j]; } return j == lp; } private static void getNextArray(String p, int[] next) { int len = p.length(); next[0] = -1; if(len == 1) return; next[1] = 0; //i: 当前要求解next[i] //cn: cn始终记录next[i - 1]的值 int i = 2, cn = next[i - 1]; while(i < len) { if(p.charAt(i - 1) == p.charAt(cn)) next[i++] = ++cn; else if(cn == 0) next[i++] = 0; else cn = next[cn]; } }}复杂度分析
设字符串 s 的长度是 N,p 的长度是 M,我们看估计 contains 方法中 while 循环体的一共执行多少次。我们设置两个量,一个是 i,一个是 i−j,其中 i 的范围 [0,N],i-j 的范围 [0,N]。
且在整个 while 的执行过程中变量 i 和 i−j 不会减小,那么这个 while 循环运行的结果就是把这两个变量不断推到最大值。可以知道这两个变量的最大值都是 N,因此 while 循环的执行次数不会超过 2N 次,因此时间复杂度 O(N)。
空间复杂度 O(N)。
测试程序
代码
import java.util.Random;public class StrContainsTest { public static void main(String[] args) { int times = 100_0000, maxStrLen = 1000; while(times-- > 0) { Random r = new Random(); int len = r.nextInt(maxStrLen) + 2; String s = getRandomStr(r, len); String p; if(r.nextInt(2) == 0) p = s.substring(r.nextInt(len)); else p = getRandomStr(r, r.nextInt(len) + 1); boolean ans1 = StrContains.contains(s, p); boolean ans2 = StrContainsKmp.contains(s, p); if(ans1 ^ ans2) { System.out.println("Oops!, wrong answer, ans1 = " + ans1 + ", ans2 = " + ans2); System.out.println("s: " + s); System.out.println("p: " + p); return; } System.out.println("Testcase: " + times + " done!"); } System.out.println("Test done successfully!"); } private static String getRandomStr(Random r, int len) { StringBuilder bd = new StringBuilder(); while(len-- > 0) bd.append((char)('a' + r.nextInt(26))); return bd.toString(); }}评论留言少 BUG !点赞转发不脱发!大家如果觉得自己的内容想让更多人知道,欢迎私信小编分享~
BY /
本文作者:victory
声明:本文归“力扣”版权所有,如需转载请联系。
")

")

")
")